


Why Data Warehouses Aren’t Enough in the AI Era
Today, data warehouses aren’t enough.
The pitch was always simple: Connect a warehouse to BI tools and you'd have analytics. That model assumes data sources and query needs stay largely static. Neither does, and data warehouse maintainers are stuck in an endless cycle of building connectors and reshaping data structures. When the world around a data warehouse moves faster than it can adapt, its usefulness falls apart.
This issue is getting worse with AI. On a weekly basis, AI agents add new tools and modify schemas, changing the source side. At the same time, they're tweaking BI dashboards, pulling data for RAG, and changing the use cases. Because we’re wrangling with a static system in a dynamic world, everything keeps breaking, and it’s why your average warehouse maintainer and warehouse user are frustrated.
How do we avoid a warehouse that's perpetually out of sync? One option is to let AI agents own the warehouse's configuration and automate maintenance. But if we've learned anything over the last few years, it’s that agents tend to degrade code quality over time. Instead, we need a system that runs parallel to the warehouse and can adapt to constant change.
That’s what we’re building at Peaka. The goal of Peaka isn't to replace a data warehouse. Warehouses still earn their keep on OLAP workloads where sources and schemas are stable enough to amortize the cost of pipeline maintenance. Instead, we're building a dynamic layer on top of your existing data infrastructure that queries and joins data at runtime, handling all the performance sub-problems under the hood. It's not as fast as a fully tuned data warehouse, but it's significantly faster than a warehouse that requires hours of engineering time just to stay in sync.
Today, we want to discuss our vision at length.
Why warehouses struggle to keep up
At the risk of over-categorizing, I want to break the problems with data warehouses into three buckets.
The shaping problem
A data warehouse’s underlying data shape is a complex problem. A warehouse isn’t just a massive USB drive. It de-normalizes data into an ordered structure so that diverse sources can be joined and collectively queried. Without this work, information would be stored in a crooked fashion and be fundamentally useless at query time.
This raises many sub-problems for engineers. How do you join an application’s Postgres state with a customer’s Stripe records? How should the web-app’s PostHog events be joined with an Amplitude instance? This is the purpose of the “T” in ETL: Transform.
To add to the chaos, many data sources produce redundant or out-of-order events: CDC pipelines emit duplicate change events, retried syncs push the same rows twice, and webhooks fire more than once. Engineers end up writing dedup logic to enforce idempotency into nearly every pipeline they own.
The moving target problem
The shaping problem is complicated by schema drift, the constantly changing inputs and outputs of warehouses.
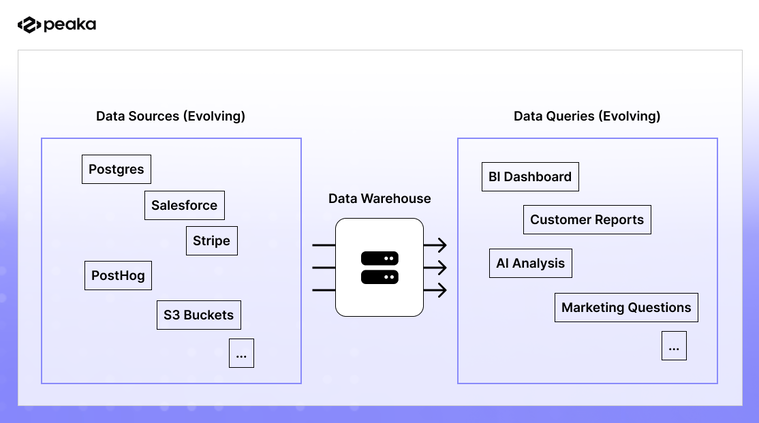
Sources change, and use cases change. New SaaS tools are added, new data stores are created by AI agents, and operators are constantly asking new questions. This puts engineers in a never-ending spiral of maintaining their data warehouse. Even well-funded data teams with mature Snowflake or BigQuery deployments feel this. The warehouse is always catching up.
The separation of duties problem
For many companies, the biggest issue is the separation of duties.
The data warehouse’s users are typically distinct from its maintainers. Operators and product teams need to query data to make decisions. But they don’t build the data warehouse; that responsibility falls on data engineers.
A warehouse's configurations trail behind real-time demand as engineers get bogged down by other tickets (especially since a warehouse is rarely considered an urgent issue), causing a lag. Even worse, indecisiveness and poor communication from operators slow down the necessary changes.
AI raises the stakes
Thus far, the answer has been more workarounds. ETL layers on top of ETL layers, pipelines slapped on top of pipelines, trying to create clean views out of already-messy data. There are entire schools of thought around navigating this complexity (the lambda vs. kappa architecture debate being a prime example).
Enter AI. AI needs data. Not just data, but metadata. It wants to know what the tables and columns mean, the relationships between them, and the statistics. For RAG, it needs recent information.
Broadly speaking, we’re entering an age of copious prompts that are data hungry. Queries that multiply into dozens of queries. A warehouse that can't keep up with these demands becomes a bottleneck for AI adoption.
Speaking candidly, it's a tricky situation. On one end, leaders are yelling "go, go, go" to integrate AI, while builders are rigging things together haphazardly. On the other end, data teams are struggling to build a data operation that can keep up, relying on Claude Code to plug the holes.
There's a different option. Keep the warehouse and add a data layer on top that queries the root sources at runtime and fills in where the warehouse falls short. That's how Peaka is designed.
Consolidation at the query level
Peaka might seem like a “yeah, but…” product. Yeah, that sounds straightforward, but what about the speed?
The skepticism isn’t unwarranted, but there are significant optimizations that can happen under the hood to deliver near-data-warehouse efficiency while keeping joins at runtime. Simultaneously, you’ll net massive benefits by using a product like Peaka:
-
Federated querying: Peaka connects directly to databases, SaaS APIs (Stripe, HubSpot, etc.), and your existing warehouses, sitting on top of them without mandatory data movement. This is an optimal design: data is accessible whenever, yet doesn’t need to be ported over prematurely.
-
Selective caching: With federation as a default, Peaka still supports optional caching. With incremental sync on configurable schedules (down to 1-minute intervals), Peaka users can achieve data warehouse performance through materialized views for BI and RAG use cases despite the data layer being virtualized. The short interval window also ensures cached content is minutes, not hours, old. This piece of the puzzle is critical when understanding Peaka alongside data warehouses: it's a dynamic layer that delivers warehouse-like performance while remaining flexible and up-to-date.
-
Semantic layer: Peaka's users compose their own views from modular building blocks without waiting on the data team. They can also publish or discover reusable data products in a shared marketplace, assembling their own data space à la carte. Especially now with AI tooling, anyone can construct a complex query without worrying about the underlying data shape.
-
Observability:** All queries are sent to Datadog, Grafana, OTel, or a built-in observability layer.
These benefits also collapse security into a single control plane: Masking, row- and column-level filtering, and user permissions are enforced once, across all connected sources.
From hand-tuned servers to managed data
We believe Peaka is part of the natural evolution of software infrastructure.
Years ago, teams hand-orchestrated servers on EC2 before Kubernetes ate the world. Now, most teams push to an orchestration platform and let it handle the complexity. Peaka applies that same philosophy to data.
Peaka doesn't ask you to rip out your warehouse. It sits alongside it, absorbing the parts of the workload your warehouse can't keep up with, and grows in scope as your sources and questions keep changing.
 Please
fill out this field
Please
fill out this field









